Safe Memory Reclamation for Lock-Free Deques: Hazard Pointers vs EBR

Memory reclamation is not something I thought I would ever do for my lock-free work-stealing deque but here we are 😬
So currently, when the deque grows and needs a bigger buffer, a new buffer is allocated and everything is copied over, but the old buffer is not deleted immediately.
Well because a thief could be mid-steal, holding a pointer to that old buffer, and if deleted that's undefined behavior.
So the easy solution was: don't delete it at all, stack all old buffers in a vector and let the destructor clean them up at end of the program.
if (b - f >= buf->capacity)
{
auto next = buf->resize(f, b);
Buffer* next_raw = next.get();
oldBuffer.push_back(std::move(next));
buffer.store(next_raw, std::memory_order_release);
buf = next_raw;
}
This method works perfectly fine, the memory cost is also bounded since we double the buffer each resize, all old buffers combined equal at most the size of the current buffer. So it's not a leak that grows unboundedly, it's O(n) extra.
But I wanted to actually reclaim that memory properly. So I implemented both Hazard Pointers and Epoch Based Reclamation, benchmarked them and picked one 🙂.
Hazard Pointers (HP)
Why is it called a hazard pointer? Honestly I wasn't sure at first either. The name comes from the paper a Hazard Pointers: Safe Memory Reclamation for Lock-Free Objects.
A hazard pointer is a published reference to an object that must not be reclaimed yet. The reference is "hazardous" because, without protection, another thread could free the object and leave the reference dangling
The core idea is a global table for each deque, one row per thread, one column per hazard pointer.
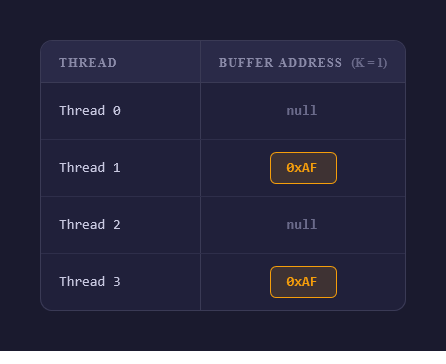
When a thief is about to steal from a buffer, it writes the address of that buffer to its own row in the table to say "Hey i am accessing this buffer"
When it's done stealing, it sets the row to null. The owner, before freeing an old buffer, scans the table and if any row contains the address of the buffer we want to free, we defer, otherwise, free it.
There's one subtle catch tho, the thief has to validate that the buffer is still valid after writing the address to the table before actually using it, because there's a race window between read pointer and publish it where the owner could have already scanned and decided nobody holds it:
auto* buf = buffer.load(std::memory_order_relaxed);
HazardGuard guard(domain.slots[id], buf); // write to table
std::atomic_thread_fence(std::memory_order_seq_cst);
// validate, did the buffer change while we were trying to write to table?
if (buffer.load(std::memory_order_acquire) != buf)
{
return std::nullopt;
}
// now safe to use buf
The fence + validate after publish is what makes it safe. Without it there would be a window where the owner scans, sees nothing, frees the buffer, and then the thief dereferences a dangling pointer.
On the owner side, resize now looks like:
Buffer* old_raw = buf;
buffer.store(next_raw, std::memory_order_release);
if (!try_free(old_raw))
{
oldBuffer.push_back(old_raw);
}
oldBuffer.erase(
std::remove_if(oldBuffer.begin(), oldBuffer.end(),
[this](Buffer* b) { return try_free(b); }),
oldBuffer.end());
Where try_free just scans all slots looking for the address:
auto try_free(Buffer* buf) -> bool
{
for (auto& slot : domain.slots)
{
if (slot.load(std::memory_order_acquire) == buf)
return false;
}
delete buf;
return true;
}
Perf numbers for steal contention vs the keep-all baseline:
| Metric | keep-all | HP |
|---|---|---|
| StealContention thread | 5.23% | 4.73% |
| StealContention itself | 1.87% | 2.62% |
| push_back | 0.87% | 0.72% |
Hazard pointers is actually slightly worse than the keep-all approach on steal contention, this makes sense as every steal now pays for two extra atomic writes (publish + clear) plus the fence + validate.
Epoch Based Reclamation (EBR)
EBR takes a different angle, instead of tracking which specific buffer each thread holds, you track which time period each thread is operating in.
There's a single global epoch counter everyone can read and when a thief enters a steal, it stamps its local slot with the current epoch number, "I started in epoch 2." When it exits, it clears to a sentinel value (UINT64_MAX, meaning inactive).
When the owner retires an old buffer, it tags it with the current epoch and sticks it in one of three limbo lists. The epoch can only advance when every active thread has caught up to the current epoch. Once the epoch has advanced twice past the epoch a buffer was retired in, that buffer is guaranteed safe to free.
Why two epochs? well because when the epoch advances, not all threads see it simultaneously, as some are still finishing operations from the previous epoch, so two full advances ensures everyone has definitely moved on.
Only three limbo lists are ever needed, retired[epoch % 3] because by the time you'd need a fourth, the first one has already been freed and recycled.
struct EpochDomain
{
static constexpr std::uint64_t kInactive = ~std::uint64_t{0};
alignas(64) std::atomic<std::uint64_t> global_epoch{0};
std::vector<std::atomic<std::uint64_t>> local_epochs;
};
And steal_front becomes:
//pin epoch FIRST, then load buffer
EpochGuard guard(domain.local_epochs[id],
domain.global_epoch.load(std::memory_order_seq_cst));
std::atomic_thread_fence(std::memory_order_seq_cst);
auto* buf = buffer.load(std::memory_order_acquire);
// no validate step needed
Notice what's gone: no validate-after-publish. The epoch pin + fence is enough. That's the key difference from HP, EBR doesn't need per-pointer validation, just a time-period stamp.
Epoch advancement on resize:
auto try_advance_epoch(std::uint64_t current_epoch) -> void
{
for (auto& slot : domain.local_epochs)
{
const auto local = slot.load(std::memory_order_seq_cst);
if (local != kInactive && local != current_epoch)
return; // someone is in an older epoch, cannot advance
}
const auto next_epoch = current_epoch + 1;
domain.global_epoch.store(next_epoch, std::memory_order_release);
// free limbo list from two epochs ago
auto& to_free = retired[(next_epoch + 1) % 3];
for (auto* buf : to_free) delete buf;
to_free.clear();
}
Perf numbers:
| Metric | keep-all | HP | EBR |
|---|---|---|---|
| StealContention thread | 5.23% | 4.73% | 3.85% ← EBR wins |
| StealContention itself | 1.87% | 2.62% | 2.70% |
| push_back | 0.87% | 0.72% | <0.09% (inlined away) |
| EpochGuard constructor | — | — | 0.53% |
EBR's steal contention thread cost drops to 3.85% , actually below the keep-all baseline. The validate-after-publish fence HP requires is visibly expensive and EBR avoids it entirely.
The owner side (push_back) is so cheap it doesn't even show up in the profile separately, it got inlined and its cost folded into the caller.
One tradeoff worth knowing: EBR is not strictly lock-free for reclamation. If a thread stalls indefinitely inside a steal (stuck in its critical region), the epoch cannot advance and nothing gets freed. HP doesn't have this problem, a stalled HP thread only blocks the specific buffer it's pointing at, not everything. For this deque with a bounded thread pool where threads don't randomly hang forever, this isn't a real concern. But it's worth knowing the formal guarantee is weaker.
Which one for Phanes?
| Metric | keep-all | HP | EBR |
|---|---|---|---|
| StealContention thread | 5.23% | 4.73% | 3.85% |
| push_back visible | yes | yes | no |
| actually frees memory | no | yes | yes |
| validate-after-publish | — | yes | no |
| reclamation lock-free | — | yes | no |
EBR!!, it's cheaper than HP on both the steal path and the owner path, it actually frees memory unlike the original approach, and the missing formal lock-freedom guarantee for reclamation doesn't matter for a fixed bounded thread pool.
The keep-all approach is still totally valid for this specific deque since resizes are rare and old buffer memory is bounded, but if we want correct reclamation without paying the HP fence tax, EBR is the right call
But wait, why is EBR cheaper?
This surprised me at first, because if you count the operations on the steal path they look almost identical.
HP steal path:
- store buf to slot (atomic write)
- seq_cst fence
- reload buffer to validate (atomic read)
- compare old vs new
- on exit: store null to slot (atomic write)
total: 2 atomic writes + 1 atomic read + 1 fence + 1 comparison
EBR steal path:
- load global_epoch (atomic read)
- store epoch to slot (atomic write)
- seq_cst fence
- load buffer (atomic read)
- on exit: store kInactive to slot (atomic write)
total: 2 atomic writes + 2 atomic reads + 1 fence
So EBR actually does one more atomic read, and yet it wins. The instruction count alone clearly doesn't explain the result.
The most visible difference in this deque is that HP has a validate-after-publish step: after publishing the buffer pointer, the thief has to reload buffer and check that it still matches, potentially retrying if a resize raced with the publication. EBR has no equivalent pointer-validation step, once the thread pins an epoch, it can load the buffer directly.
My current belief is that this extra reload/compare/retry path is what makes HP slower in this workload, but I have not yet confirmed that with hardware-counter profiling. So treat this as an explanation of the likely cause, not a formal proof.😏
But one thing, EBR is not the universal answer. It won here because of what Phanes is: a bounded thread pool where threads enter and leave their critical sections quickly and never hang forever, and where reclamation only happens on rare resizes, because if threads can stall arbitrarily inside a critical region, EBR's epoch can't advance and memory just piles up.
So the real takeaway isn't "EBR beats HP." It's that the right reclamation scheme falls out of the structure of the lock-free thing you're building, how long critical sections last, how many threads there are, whether they're bounded, and how often you reclaim. So benchmark your own workload 🫵🏽, the answer lives in your access pattern.
Full Code at Phanes-deque.cpp
Further reading
- Jeffrey Mendelsohn - Introduction to Epoch-Based Memory Reclamation
- Applying Hazard Pointers to More Concurrent Data Structures
- Manuel Pöter Effective Memory Reclamation