Build systems -C++ (PART 2)

After going through the previous post on build systems, I felt there was a need to go in-depth with examples
But first we have to understand how compilation and linking works in C/C++ as it is vital to know how the pipeline produces the executable and library files from the source code in other to fully understand why build systems are important.
and PS: for this article let's assume we are following cpp best practices 😁
We know that all cpp code bases or projects have source files (.cpp) and header files (.hpp). The header file usually contains enumerations, macros, declarations of functions, global variables, and structures while the source files contain the function definitions. For this article we would create a simple c++ program with 3 files
- A header file - test.hpp
The file contains only one function
addNumberdeclaration and is also protected by the header guard statements as this prevent the header file from being included twice or more while being compiled
#ifndef TEST_HPP
#define TEST_HPP
int addNumbers(int num1, int num2);
#endif
- A Source file - test.cpp This file contains the header file and the definition of the function, the function simple returns the sum of two numbers passed in as variables
#include "test.hpp"
int addNumbers(int num1, int num2){
return num1 + num2;
}
- Another Source file - main.cpp The main function is the entry point of the program, the main function calls the addNumber functions with arguments
#include <iostream>
#include "test.hpp"
int main() {
std::cout<<addNumbers(2,3);
}
Building 🙂
To build the project and create an executable means that we will compile all the sources within its code base to first produce some object files and finally combine those object files to produce the final products, such as static libraries or executables.
Yes you read that right 😑 , if they are 1000 source files, we have to compile them one after the other this means that we have to run the compiler 1000 times!. 😫

Now let's see what goes on behind the scenes
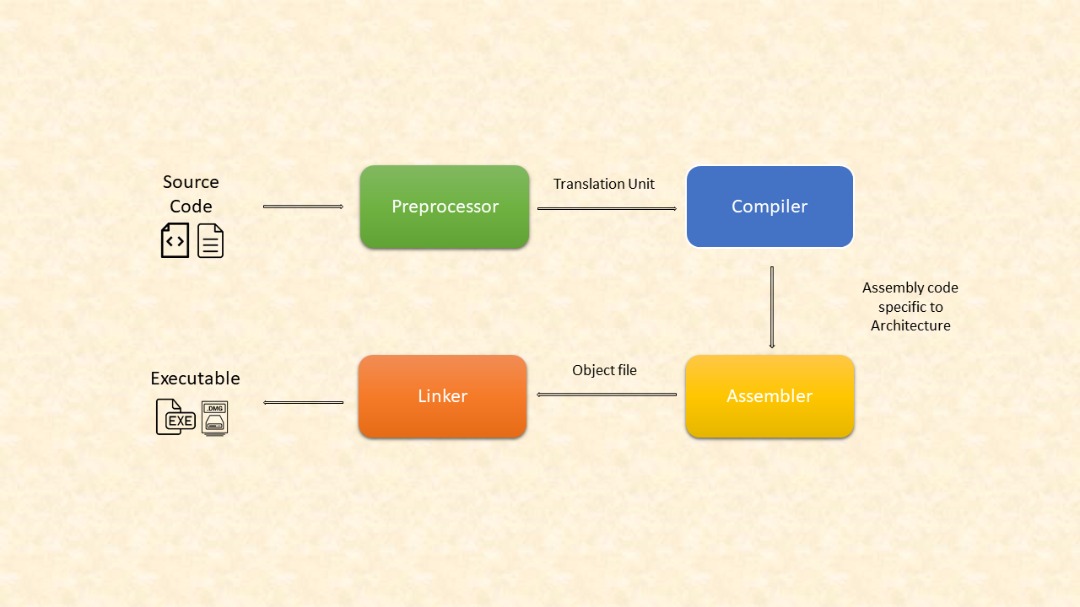
The source code is fed through a pipeline with four unique sections, each of which performs a specific task. Each section in this pipeline takes a specific input from the one before it and creates a specific output for the section after it. This procedure continues along the pipeline until the last section generates a product. These sections are as follows:
- Pre-processor
- Compiler
- Assembler
- Linker
Let's go in-depth a bit 😌😌
- Pre-processing: This section simply copies the content of the header files and resolves the pre-processor directives, the output of this section is a translation unit
To see the translation unit of your code, use this command :
$ gcc -E test.cpp
running this same command with main.cpp will produce a large input because it contains iostream library
- Compiling: Here the input is the translation unit from the pre-processor, which parsed and scanned by the compiler. The compiler also optimized and performance type checking, its output is an assembly code specific to your target architecture (x86, ARM etc)
To see resulting assembly code, use the command bellow, it dumps the output in a .s file in same folder
$ gcc -S main.cpp
- Assembling: this generates machine code (object file) from the assembly code. Each architecture has its own assembler, which can translate its own assembly code to its own machine code. Note that object code does not know the final memory addresses in which it will be loaded, thats why it is not executable.
$ gcc -C main.cpp
note that preprocessing, compilation, and assembling are done as part of the preceding single command and it generates a .o file that unfortunately, we cant open 🤷
- Linking: we still haven't gotten a product from all the steps above, also we have 2 object files generated from the 2 source files we have. This section combines those object files, selects a final memory location to form a final program
Okay, okay back to build systems 🤓....
If we want to build the above project without using a build system, we must run the following commands in order to build its products. Note that I used Linux as the target platform for this project:
mkdir -p out
g++ -g -o main.o -c main.cpp
g++ -g -o test.o -c test.cpp
g++ main.o test.o -o main
./main
but then this commands can grow as the number of source files grows. you can actually maintain the preceding commands in a shell script file but then questions like..
- can I run the same commands on all platforms? i.e portability
- What happens when a new directory or file is added to the project? Do we have to keep manually editing the shell script tho accommodates new stuffs?
- What happens if we need a new product, like a new library or a new executable file
Let's try Makefiles, I am going to try to write a makefile for this, please don't judge I am not good with make, so here goes nothing 🙈
build: main.o test.o
g++ main.o test.o -o build
main.o: main.cpp
g++ -c main.cpp
test.o: test.cpp test.hpp
g++ -c test.cpp
clean:
rm *.o build
Trust me, if you are as lazy as I am, you definitely don't want to write makefiles ! 🏃🏾♂️😂
So how is this different from the shell script file we wrote before 🤔, well unlike shell files makefiles include a lot of control flow mechanisms (loops, conditions, and so on), we can declare a variable in a Makefile and use it in various places, make files can also check for recent modifications in a file, if there are none it skips the build and trust me, you can not get this features in shell scripts
Interesting but... if you have the source codes and makefile of a C++ project from your Linux machine, you cannot directly build that code inside Windows OS and vice versa!, so it still lacks portability 🤷 this is where CMake comes in and cmake even generates the makefiles for you automatically, whhew 😫
Okay that sums it up, there are other amazing build systems one might still consider such as GNU Autotool, I plan to give it a try soonest 🙂!